
내가 보려고 만든 블로그
LDA 토픽 모델링 - (Gibbs Sampling , VI 를 통한 구현 ) 본문
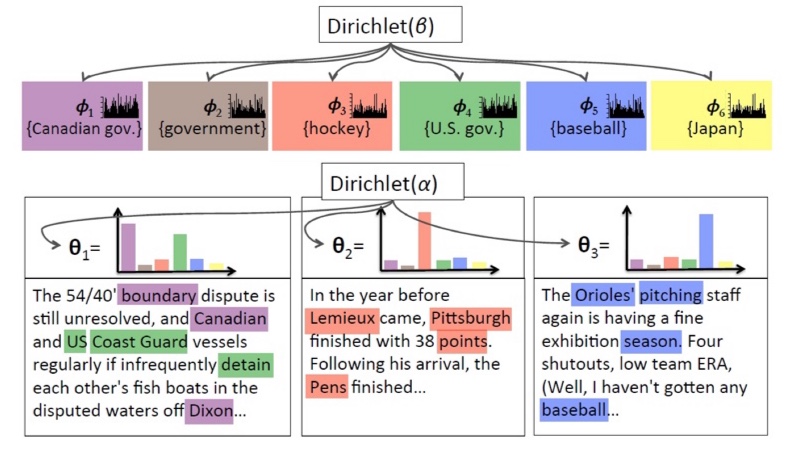
Topic 모델링이란 어떠한 문서를 주제의 확률 분포로 표현하는 것이다.

예컨대 신문의 기사들이 경제 ,스포츠 , 연예 3가지 주제만을 가진다고 해보자. 경제 뉴스에는 당연히 경제와 관련된 단어들이 많이 분포할 것이다. 하지만 그렇다고 해서 경제에서 사용되는 단어뿐만이 아니라 스포츠 , 연예 등에서 사용하는 단어들이 존재 할 수있다. 이렇게 한 문서 안에서 단어들의 주제를 파악하고 그 단어들의 분포를 통해 한 문서를 주제의 분포로 나타낼 수 있다.

LDA 를 검색하면 가장 많이 나오는 그림이 바로 위와 같은 그림일 것이다. 오른쪽 부터 ,
베타는 주제 X 문서의 Dirichlet 분포를 결정하는 Hyperparameter ,피(k) 는 주제X문서의 분포이며 K는 주제들의 집합이다.
알파는 단어X 문서의 Dirichlet 분포를 결정하는 Hyperparameter , 세타는 단어X문서의 분포, z_m 은 해당 문서에서의 주제 , x_mn 은 문서 M에 속한 단어 , N_m은 문서 M 에서 나오게 된 단어의 집합 , M은 Documents 들의 집합 이다.
+ 11/19 추가 이걸 보는게 더낫겠다 위 설명보다

Dirichlet 분포란?
여기서 잠시 Dirichlet 분포란 무엇이고 왜 LDA 에서 사용하는 것 일까?
이항분포는 발생할 수 있는 사건이 2가지 일 경우에 사용될 수있는 분포이다. 여기서 발생가능한 사건의 수를 k개로 확장한 것이 다항분포이다. 그리고 베타분포는 a,B 2가지 모수를 가지게 되는데 사건이 발생한 횟수가 a-1 , 발생하지 않은 횟수가 B-1 임이 관찰되었을때 사건이 발생할 확률 p를 분포로 나타낸 것이다. 이항분포에서 다항분포로 확장했듯이 베타분포를 k개의 사건이 발생가능한 경우로 확장한 것이 바로 Dirichlet 분포이다. 수식은 다음과 같다.
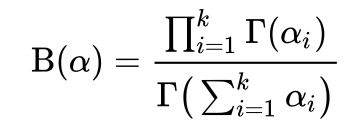
깁스 샘플링
자 이제 문서내 단어들을 주제에 할당하고 문서를 주제들의 분포로 표현하기 위하여 깁스샘플링에서는 다음과 같은 과정을 거친다.
1. 초기에 단어들에 대하여 랜덤하게 주제를 할당한다.
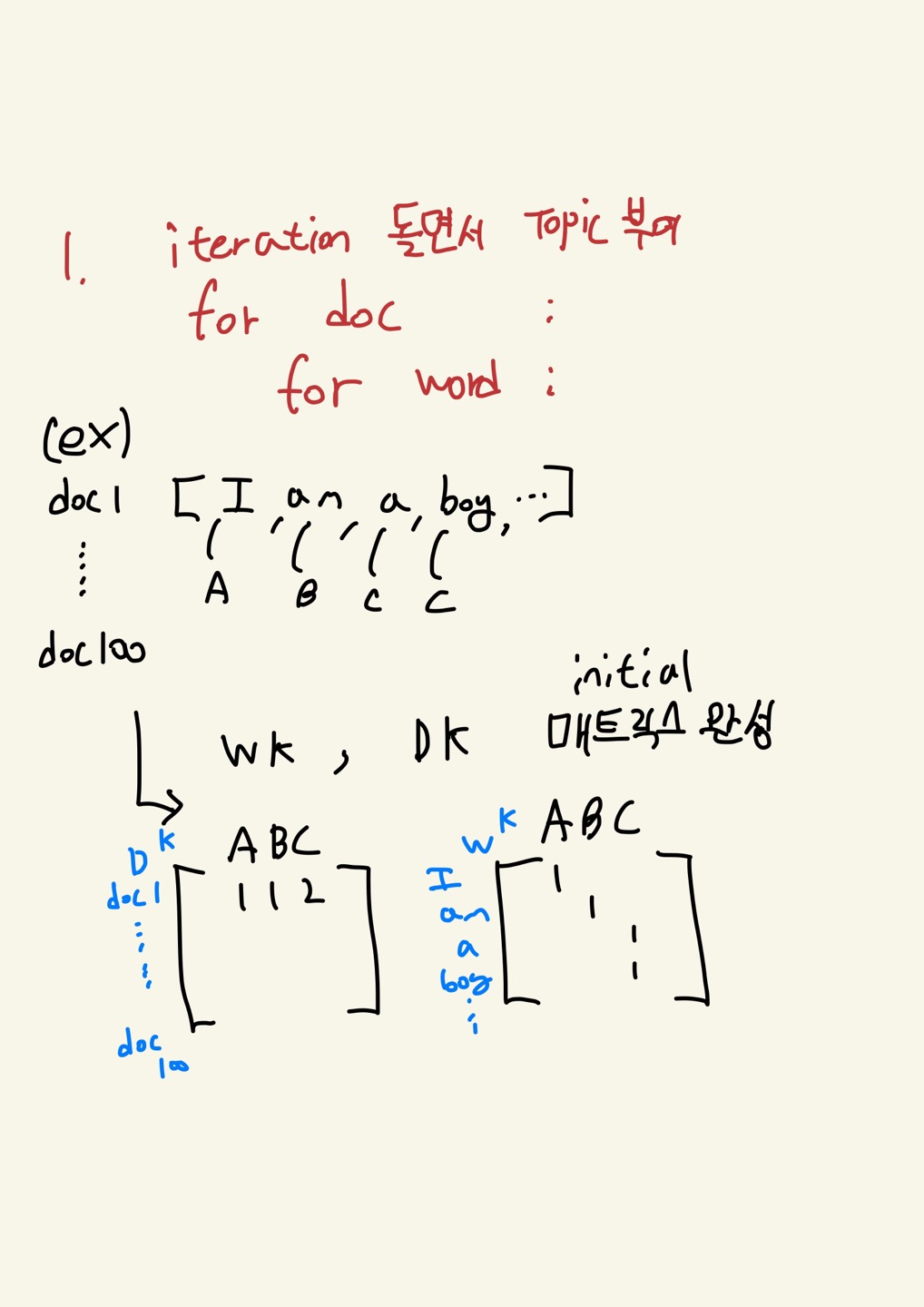
2. n번째 단어에 대하여 그 단어를 제외한 분포에서 다시 샘플링하여 새로운 주제를 할당한다.
위 과정을 충분히 수렴할때까지 반복한다.

깁스샘플링을 이용하여 구현한 코드:
https://github.com/todtjs92/NLP/tree/master/LDA_GibbsSampling
GitHub - todtjs92/NLP: NLP와 관련된 프로젝트와 관련된 코드들
NLP와 관련된 프로젝트와 관련된 코드들. Contribute to todtjs92/NLP development by creating an account on GitHub.
github.com
Variational Inference

샘플링을 통해 사후분포를 구하는 것은 아무래도 꽤 정확한 사후분포를 구하는데에는 많은 샘플들이 필요하게 되고 시간이 오래걸리게 된다.
사후분포를 구하기 위한 다른 방법으로 Variational Inference가 있는데 VI의 여러 방법중 Mean Field Approximation 을 이용해 LDA를 구현하였다. Variational Inference는 사후분포를 직접적으로 구하는 것이 아니라 최대한 사후분포에 대하여 근사하는 분포 = q를 구하는 방법이다. 분포 q에 대해서 Mean Field 방법은 사후분포를 구함에 있어 필요한 각각의 Latent Variable들을 또 여러개의 분포들을 이용하여 근사하는 방법이라고 볼 수 있다. 이 때 여러개의 분포들은 서로 독립이다는 가정을 넣어 계산상의 이점을 넣는다. 예를 들어 , 가우시안 믹스쳐 모델에서 특정분포를 여러개의 독립적인 정규분포를 이용하여 표현하는 것과 비슷하다.
1. 초기에 각 문서의, 단어들에 대하여 임의로 토픽을 배정하는 것은 똑같고
2. 이후에 깁스샘플링과 비슷하게 2,3을 fix한 체로 1을 업데이트 시키고 1,3 을 fix후 2 업데이트 , 1,2를 fix 후 3 업데이트 와 같은 방법으로 충분히 수렴할 때 까지 반복한다.
Variational Inference 구현
https://github.com/todtjs92/NLP/tree/master/LDA_VarianceInference
GitHub - todtjs92/NLP: NLP와 관련된 프로젝트와 관련된 코드들
NLP와 관련된 프로젝트와 관련된 코드들. Contribute to todtjs92/NLP development by creating an account on GitHub.
github.com
'Data Science > NLP' 카테고리의 다른 글
| <NLP> Transformer 정리 ~ 허깅 페이스까지 (1) | 2022.09.05 |
|---|
